As promised in part 2 of this series, I have some interesting benchmarks of the different hash map variants. In this part I will discuss the results, and present my conclusions. Click any benchmark to get a much larger graph.
How I Benchmark
I’m inserting 100 million int -> int pairs into different hashmap variants, and every 100000 inserts I am taking measurements (insertion time, memory usage, time to lookup 1 million elements, where half of the lookups fail.). As a hash function I am using std::hash. My computer is an Intel i5-4670 @ 3.4 GHz, 16GB RAM, Visual Studio 2015 Update 3, 64bit.
Insertion Time Benchmark
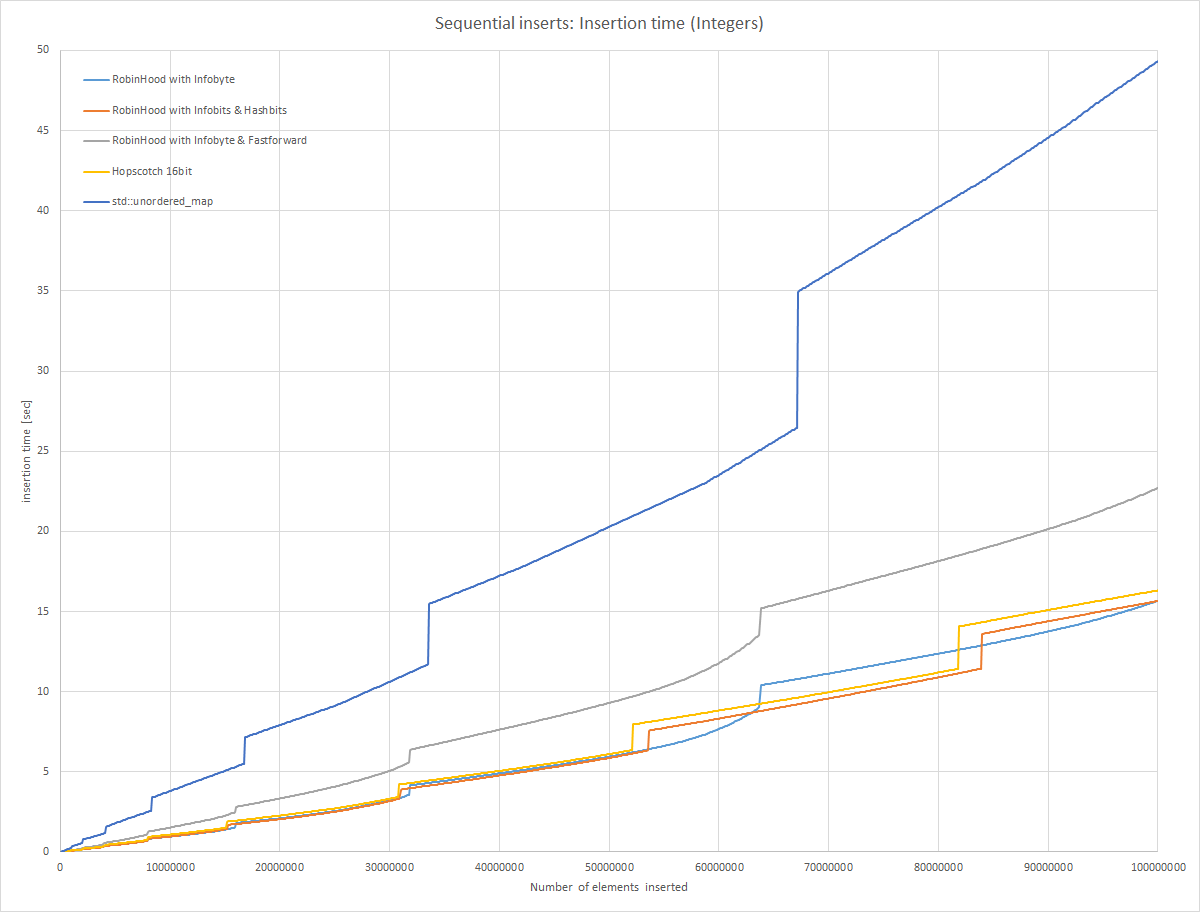
In this graph the reallocations are very clearly visible. All variants are doubling the size of the internally used array when it gets full. As expected in part 2, it can be seen that insertion time slows down when “Robin Hood with Infobyte” gets full, and also when “Robin Hood with Infobyte & Fastforward” gets full. This is due to the fact that more and more data needs to be moved around so the hashmap can stay sorted.
Dealing with the fastforward field has a clear overhead associated with it, insertion is quite a bit slower.
For “Robin Hood with Infobits and Hashbit”, insertion time is very fast: mostly because the offset is limited to 16, if it would get larger the hashmap’s size is doubled. Hopscotch insertion is almost as fast, just a tad slower.
All variants are much faster than std::unordered_map. The comparison is a bit unfair, because in my implementations I do not have to support the same interface as std::unordered_map does.
Memory Usage
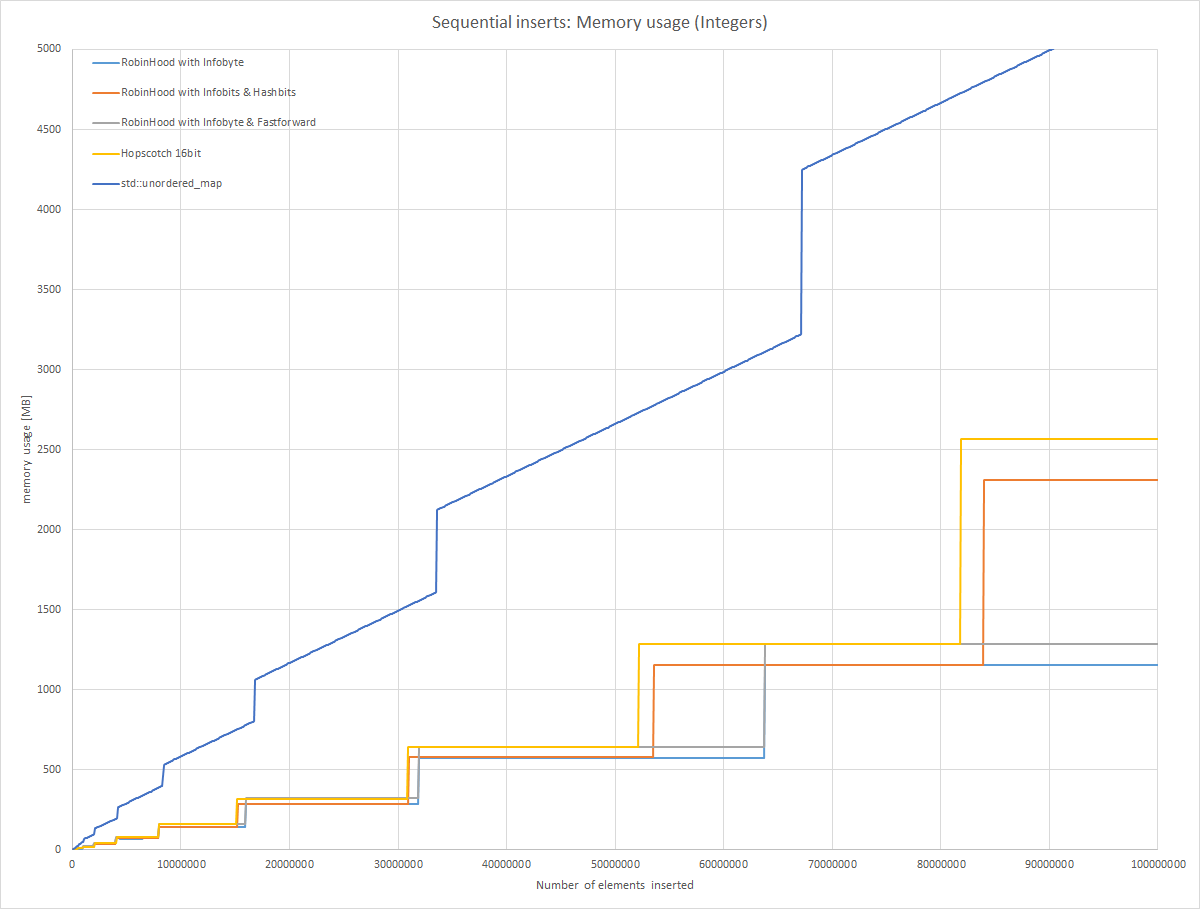
Robin Hood with Infobyte is the most compact representation. I am resizing the map when it gets 95% full, or when an overflow occurs which is highly unlikely when using an appropriate hash function. There is just 1 byte overhead for each entry.
The second best representation is “Robin Hood with Infobyte & Fastforward”. This has exactly the same reallocation properties as when just using the infobyte, but it uses one additional byte per bucket.
When limiting the maximum offset as in “Robin Hood with Infobits & Hashbits”, resizes are occuring much quicker (maximum offset is 15 instead of 127), so the memory usage jumps up earlier.
For Hopscotch this reallocation seems to happen still a bit earlier. The overhead in my implementation is 16 bit, so the line overlaps a lot with the Infobyte & Fastforward variant.
All my implemented variants need much less memory than std::unordered_map. While std’s implementation allocates new memory for each insert, in all my variants the memory stays constant until reallocation occurs.
Lookup Time
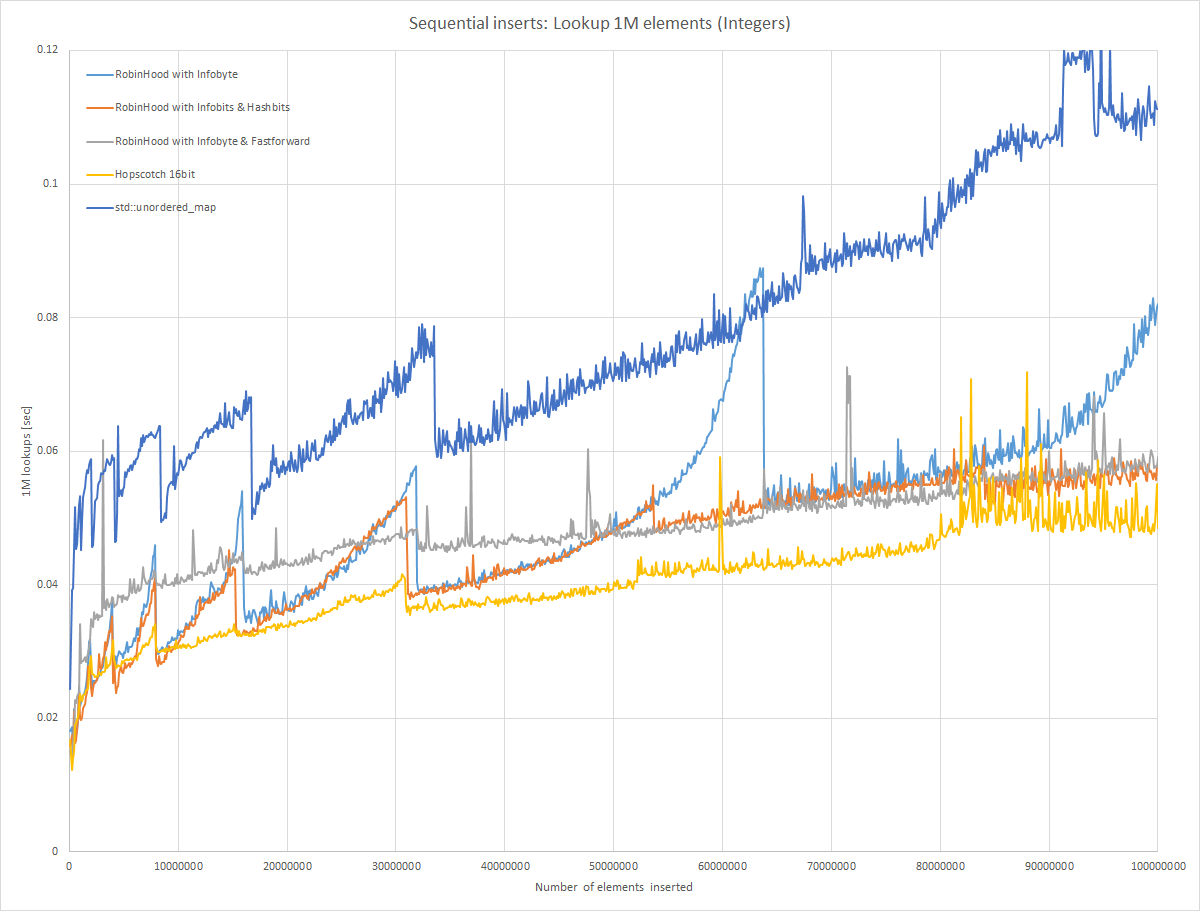
This is probably the most interesting benchmark for most use cases, and I find this graph extremely educational and interesting.
First, the Robin Hood with Infobyte variant: Lookup time starts pretty fast, but it gets slower and slower as the hashmap gets full. This is due to the longer and longer chains that needs to be traversed to find the correct element. So the highly compact format is bought with ever increasing lookup (and insertion) times. Still, lookup is almost always faster than lookup for std::unordered_map.
The Robin Hood with Infobits & Hashbits variant shows the same behaviour, lookup time goes up when the hashmap gets full. This increase is capped early though due to the earlier reallocations. So faster lookup times can be bought with earlier reallocations and more memory usage.
To improve lookup times compared to the infobyte variant, I have introduced the fastforward byte to quickly skip directly to the elements that belong to a bucket. That’s the gray line. When the hashmap is quite empty it seems that extracting this fastforward information has quite a bit of an overhead. When implementing this variant I did not expect such a large overhead. It seems to work very well though in improving lookup time when the map gets very full, as can be seen around the 60 million elements line. Here, lookup for the variant with just the infobyte takes 0.0676 seconds, and when using fastforward byte it takes 0.0487 seconds, 38% faster. Also the lookup time is quite linear.
Last but not least, the Hopscotch variant. After spending quite some time tuning, this variant turned out as the fastest of all. Lookup time does not have the spiky behaviour that robin hood has, and it is extremly fast. One trick I am using is that I using that I didn’t see anywhere else mentioned, is that I shift the whole hop field and can stop the while loop as soon as the hop field is zero. So when only one element is there and it is in the first bucket, I need to check just one bit of the hopfield. When the element is not there, hopfield is zero so no bits have to be checked at all.
Summary
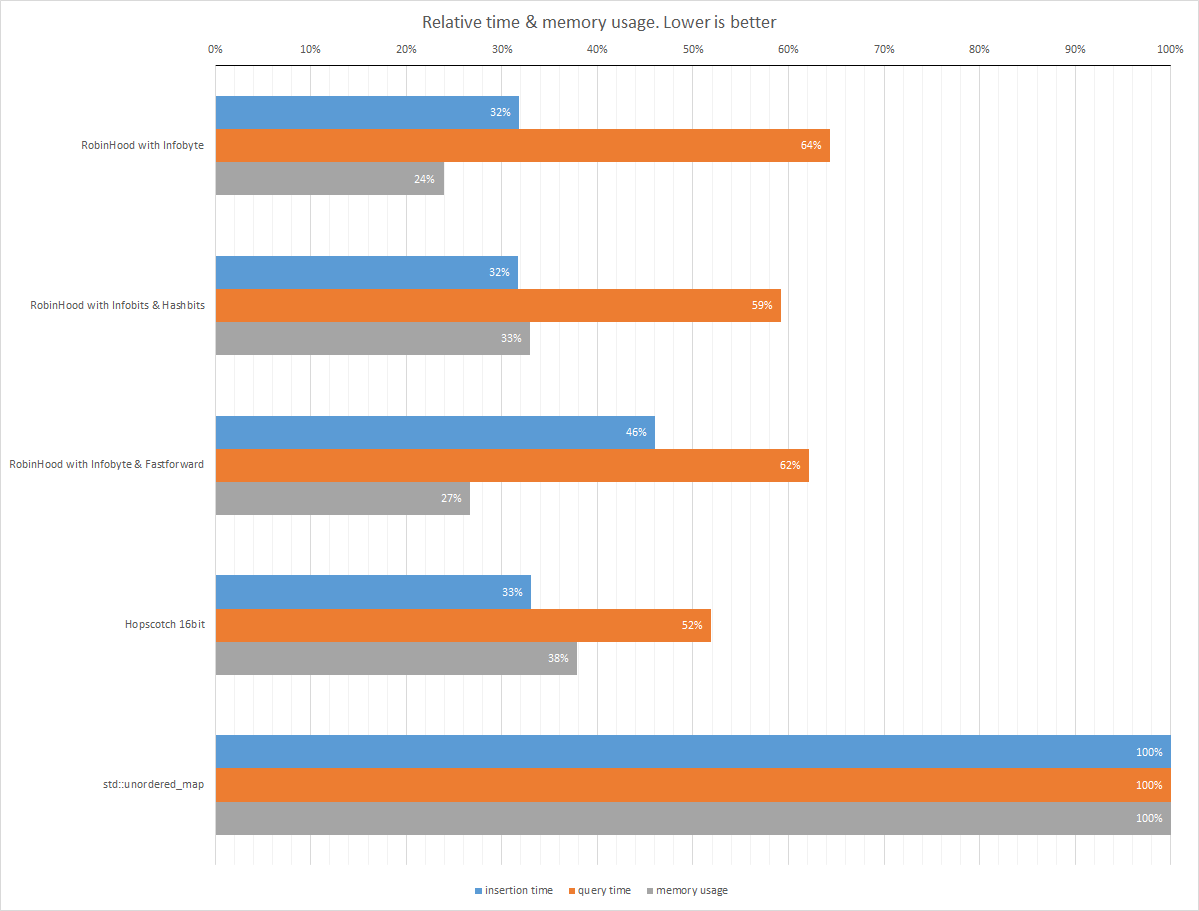
I’ve summed up the average insertion time, average lookup time, and average memory usage over all the different samples. std::unordered_map is the reference with 100%. Here are my conclusions:
-
The HopScotch implementation is the best overall for most use cases, if you have a reasonable hash function. Insertion time is just a tad slower than the fastest variant, memory usage is a bit higher than the other variants but still almost 3 times better than
std::unordered_map, and lookup is blazingly fast with almost twice the speed asstd::unordered_map. 0.0404 seconds to look up 1 million elements, or just 40.4 nanoseconds per lookup on average is not too shabby. -
If your hash function is bad or compactness is of utmost importance, use the Robin Hood with Infobyte variant.
-
If the
stdinterface is important, stick tostd::unordered_map. While it uses lots of memory, lookup times seem to be ok and fairly consistent.
That’s my tour of hashtable implementations. You can find my code on Github at martinus/robin-hood-hashing. It still needs lots of cleanup, and most importantly, the ability to remove elements…